PODSTAWY – CZĘŚĆ 2
W drugiej części naszego wprowadzenia w dalszym ciągu poruszamy się w zakresie zagadnień ogólnych. Wiedza ta jest jednak niezbędna do lepszego zrozumienia kolejnych części niniejszego opracowania. W rozdziale tym znajdą Państwo dodatkowe informacje jak i kryteria, które wydatnie pomagają w dokonaniu świadomego wyboru rodzaju sieci przemysłowej dla określonej aplikacji.
Poniższe opracowanie porusza następujące zagadnienia:
– przepustowość danych netto;
– czasy opóźnień, czasy reakcji, jitter;
– zdolność do pracy w czasie rzeczywistym, synchronizacja;
– poziom utraty danych, poziom błędów resztkowych;
– różnorodność, modularność i inne aspekty ekonomiczne;
Przepustowość danych netto
Każdy zdefiniowany i znormalizowany interfejs komunikacyjny posiada własny sposób przysłania informacji oraz zdefiniowaną strukturę “ramki” danych. Dane “Netto” oznaczają faktyczną informację, a więc jest to odzwierciedlenie dokładnej odpowiedzi na zadane pytanie. Samo “opakowanie”, definicją i kształtem odpowiadające parametrom określonej sieci przemysłowej, zawiera dodatkowe, niezbędne składniki do odczytania przesyłanej wiadomości.
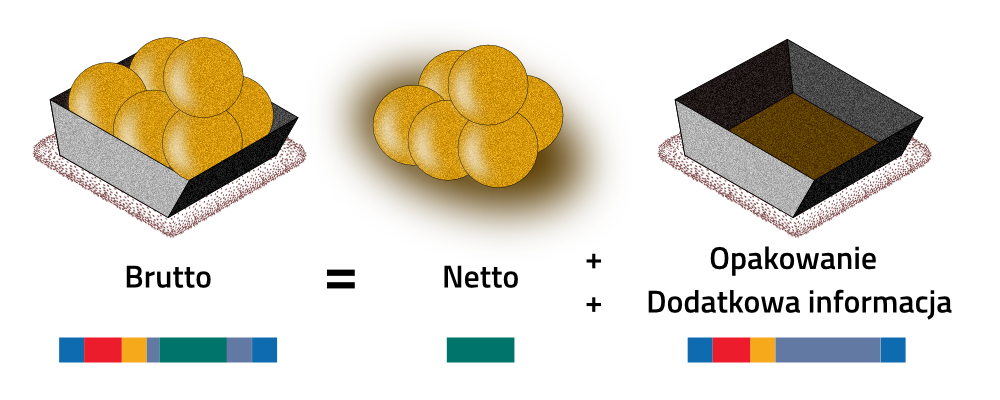
Wśród parametrów, które określają informacje “brutto” w systemach sieciowych znajdujemy:
![]() konieczną i wymaganą minimalną przerwę pomiędzy dwoma wiadomościami;
konieczną i wymaganą minimalną przerwę pomiędzy dwoma wiadomościami;![]() bity start i stop oraz informację na temat synchronizacji;
bity start i stop oraz informację na temat synchronizacji;![]() adres oraz inne informacje identyfikacyjne;
adres oraz inne informacje identyfikacyjne;![]() zabezpieczenie danych;
zabezpieczenie danych;![]() minimalną długość telegramu;
minimalną długość telegramu;
|
Każdorazowo netto / brutto = procentowa wydajność przesyłu danych |
 |
Przyjrzyjmy się teraz dokładniej powyższym parametrom.
Minimalna przerwa pomiędzy telegramami
Minimalna przerwa między dwoma, następującymi po sobie wiadomościami jest wymagana w celu odseparowania i rozróżnienia kolejnych telegramów. W czasie trwania przerwy sieć znajduje się stanie bezczynności.
Bit Start, Stop oraz informacja synchronizacyjna
Elementy te są wykorzystywane w celu synchronizacji nadajnika i odbiornika w taki sposób, żeby telegramy były przesyłane bez żadnych zakłóceń. Różnią się one w zależności od rodzaju sieci przemysłowej.
Adres i dane identyfikacyjne
Adres w jednoznaczny sposób identyfikuje urządzenie odbierające (w niektórych wypadkach również i nadajnik) do którego, lub z którego, wysyłana jest dana wiadomość. Identyfikator definiuje natomiast rodzaj wysyłanego objektu (typ zapytania/informacji).
Zabezpieczenie danych
Jest to środek techniczny, którego celem jest zabezpieczenie przesyłanych danych względem możliwych błędów transferu i zakłóceń wpływających na jakość wymiany informacji.
Minimalna długość telegramu
Specyfikowana minimalna długość informacji określa minimalną ilość bitów i bajtów przesyłanych w jednym telegramie. Jest ona zawsze ściśle określona przez specyfikację danej sieci przemysłowej.
Minimalna długość telegramu pozwala nam na uproszczoną kategoryzację systemów sieciowych (o czym wspominano w pierwszej części: Podstawy – Część 1):
– systemy zorientowane na bit (minimalna długość telegramu 1…4 bity)
– systemy zorientowane na bajt (minimalna długość telegramu 1 bajt)
– systemy zorientowane na blok (minimalna długość telegramu 1 blok, np. 64 bajty)
Należy pamiętać, że to koszt jest zawsze wartością decydującą przy projektowaniu każdego systemu sieciowego. Tylko wystarczająco wydajne systemy są rozwiązaniami konkurencyjnymi.
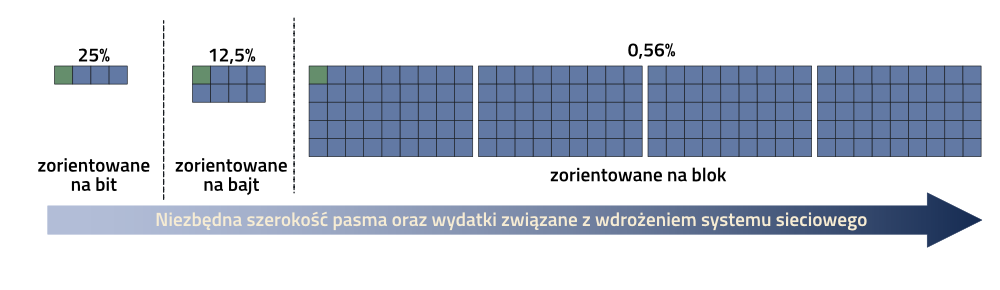
Przepływność danych powinna być zawsze ważnym kryterium oceny wybieranego rozwiązania. Ilustrację pomocniczą przedstawia powyższy rysunek. Określa on procentową wartość przesyłu danych dla jednego bitu informacji, np. komendy “START”, przesyłanego w różnych systemach sieciowych. Biorąc pod uwagę minimalną ilość przesyłanych informacji można szybko dostrzec, że systemy zorientowane na bajt, a jeszcze bardziej systemy blokowe, przesyłają znaczne ilości zbędnych, nigdzie niewykorzystywanych informacji.
|
Im wyższa przepustowość danych brutto, tym większa konieczna przepustowość systemu sieciowego, a tym samym tym wyższe koszty ekonomiczne implementacji danego rozwiązania. |
|
Istotne jest, że wraz ze wzrostem przepustowości danych brutto:
![]() przewody komunikacyjne stają się coraz bardziej złożone, a przez to droższe;
przewody komunikacyjne stają się coraz bardziej złożone, a przez to droższe;![]() elementy nadajników i odbiorników stają się bardziej wrażliwe na wszelkiego rodzaju zakłócenia;
elementy nadajników i odbiorników stają się bardziej wrażliwe na wszelkiego rodzaju zakłócenia;![]() sam projekt i instalacja systemu sieciowego obwarowany jest większą ilością koniecznych do spełnienia wymagań;
sam projekt i instalacja systemu sieciowego obwarowany jest większą ilością koniecznych do spełnienia wymagań;
Wnioskując, przy projektowaniu systemu, tzn. przy wyborze odpowiedniego systemu sieciowego dla określonej aplikacji, należy zwrócić uwagę przede wszystkim na przepustowość danych netto danej sieci, a najlepiej na przepustowość danych netto przypadającą na każdego uczestnika wymiany danych.
Czasy opóźnień, czasy reakcji, jitter
Kolejnym bardzo istotnym kryterium oceny przydatności systemu sieciowego są wszystkie czasy opóźnień występujące podczas normalnej pracy i standardowej wymiany danych.
Poniżej krótka informacja jak ten aspekt wygląda w odniesieniu do kolejnych stadiów rozwoju automatyki przemysłowej:
Kiedy systemy sterujące były w pełni zależne od logiki operacyjnej opartej na rozwiązaniach przekaźnikowych zadania jak np. “Utrzymanie stanu wypełnienia zbiornika wody na określonym poziomie” był wykonywane wg schematu:
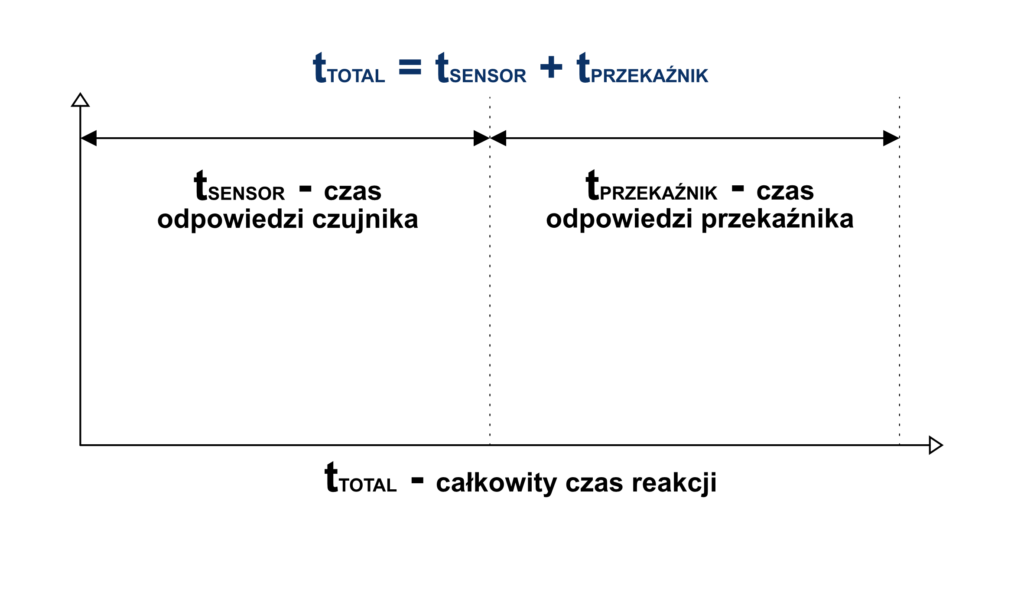
Całkowity czas uzyskania reakcji systemu w momencie spadku poziomu poniżej ustalonego punktu jest równy czasowi reakcji czujnika, oraz czasowi odpowiedzi samego przekaźnika odpowiedzialnego za załączenie pompy. Tak określony czas reakcji będzie zawsze taki sam.
Od chwili, kiedy na rynku pojawiły się układy kontrolne oparte na niedrogich sterownikach PLC, układy logiczne oparte na przekaźnikach są systematycznie wycofywane z użycia, a na dzień dzisiejszy bardzo rzadko spotykane. Oczywiście, w aplikacjach rzeczywistych, sterowniki PLC pełnią znacznie więcej zadań niż kontrola jednego punktu przełączania. Dla potrzeby niniejszego opracowania nie będzie to jednak brane pod uwagę.
Bazując na takim założeniu technicznym, ilość czasu jaki upłynie od detekcji poziomu minimalnego do załączenia pompy może być przedstawiona w następujący sposób:
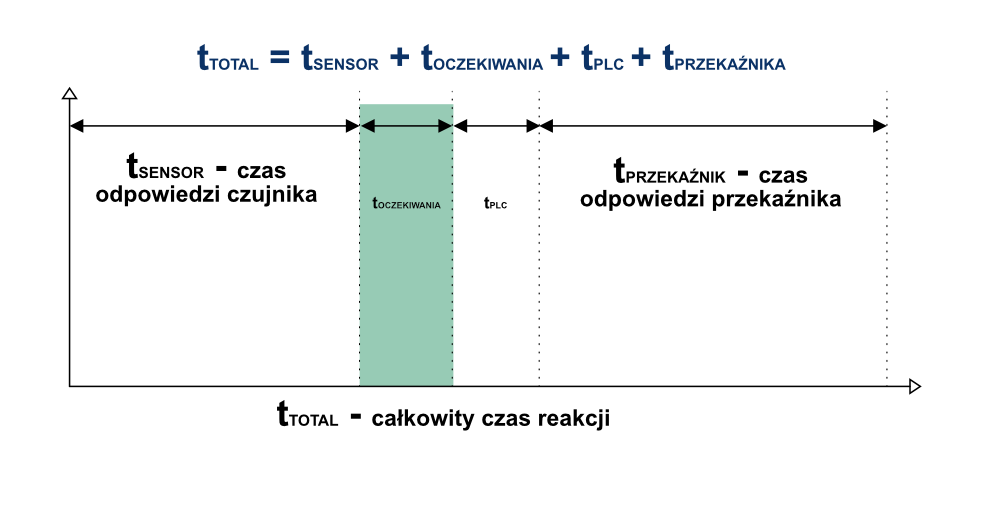
Każdy sterownik PLC pracuje cyklicznie, a sam czas skanowania programu określono tutaj jako tPLC. Jeśli określone zdarzenie (spadek poziomu wody) nastąpi w dowolnym czasie, pojawi się czas opóźnienia (oczekiwania), wynoszący dokładnie tyle, ile wymaga sterownik do przetworzenia zdarzenia i inicjacji odpowiedniej reakcji. Jest to tzw. czas synchronizacji. Takie zachowanie jest typowe dla sterowników działających sekwencyjnie. Czas trwania opóźnienia wynosi od zera do maksymalnie czasu trwania cyklu sterownika PLC. Z uwagi na tę cechę, całkowity czas reakcji nie będzie zawsze jednakowy, lecz ma wartość średnią, rozproszoną wokół tej wartości. To rozproszenie nazywamy jitterem.
W chwili kiedy standardowe okablowanie (punkt-punkt) zostaje zastąpione systemem sieciowym w równaniu pojawiają się nowe zmienne:
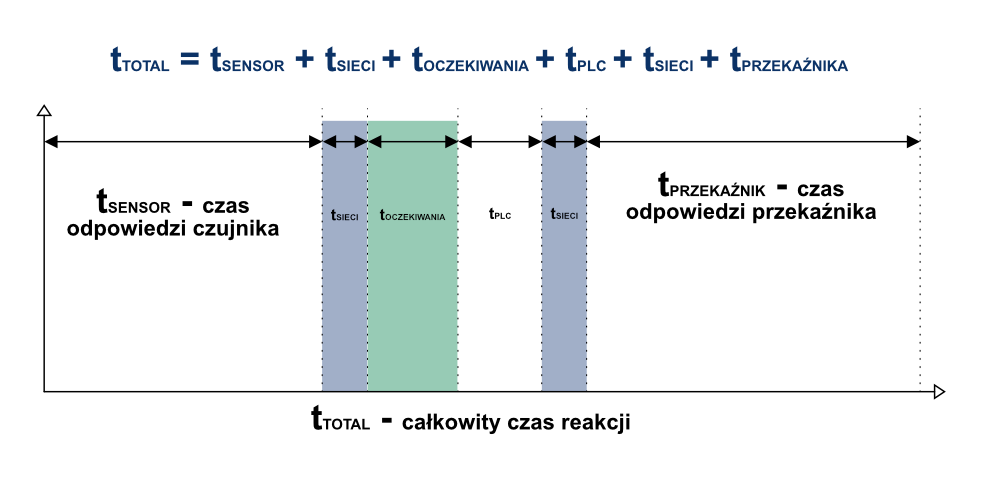
W przeciwieństwie do przedstawionego wcześniej rozwiązania, opartego na sterniku PLC i połączeniu bezpośrednim, teraz należy doliczyć czas potrzebny na przesłanie sygnału przez magistralę polową. Ten czas występuje dwukrotnie: najpierw przy odbieraniu sygnału z czujnika (wejście logiczne) a następnie, po określeniu przez program PLC odpowiedniej reakcji, przy przesyłaniu wymaganego sygnału aktywującego przekaźnik (wyjście logiczne). Z reguły te dodatkowe opóźnienia wynikające z zastosowania systemu sieciowego są na tyle małe, szczególnie w porównaniu z innymi czasami zwłoki, że mogą być pominięte. Z uwagi na rosnące zapotrzebowanie na szybszą wymianę danych w zautomatyzowanych systemach sieciowych może się jednak okazać konieczne wzięcie tych czasów pod uwagę podczas projektowania nowego rozwiązania.
Przyglądając się uważnie czasowi opóźnienia systemu sieciowego można zauważyć, że zależy on od trzech podstawowych czynników: ![]() prędkość przesyłu (przepustowość sieci netto);
prędkość przesyłu (przepustowość sieci netto);![]() liczba uczestników wymiany danych;
liczba uczestników wymiany danych;![]() metoda dostępu do magistrali;
metoda dostępu do magistrali;
Metody dostępu do magistrali opisano w pierwszym rozdziale wstępu (TUTAJ). Przyjrzyjmy się im teraz dokładniej z punktu widzenia opóźnienia w przesyłaniu danych.
Dla metody Master-Slave z cyklicznym odpytywaniem, Master wywołuje kolejno wszystkie podłączone moduły podrzędne i odczytuje ich odpowiedzi. Dla tej metody możliwe jest dokładne określenie czasu trwania cyklu. Należy jednak pamiętać, że sygnał z danego urządzenia może być przekazany do Mastera, czy też nadrzędnego systemu sterownia, tylko w momencie kiedy dany Slave zostanie wywołany.
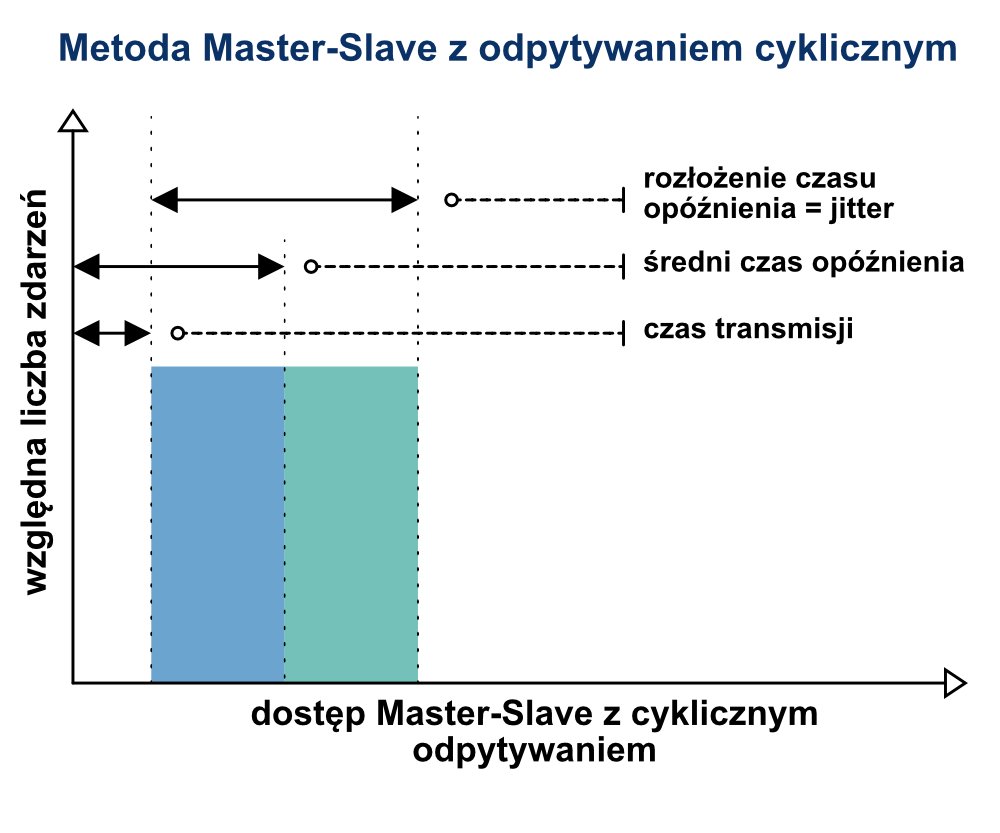
Dlatego też w takim rozwiązaniu czasy opóźnień mieszczą się miedzy zerem a czasem trwania cyklu. Do pełnego rachunku konieczne jest oczywiście dodatnie określonego czasu transmisji. Największą zaletą takiego rozwiązania jest możliwość dokładnego określenia maksymalnego czasu opóźnienia.
Zarówno metoda TDMA jak i metoda przekazywania tokena wykazują podobne zachowanie wszędzie tam, gdzie udaje się ustalić maksymalny czas przekazania prawa komunikacji (tokena).
W przypadku metody CSMA każdy moduł podrzędny, który wykryje zmianę na swoich wejściach, może natychmiast przesłać tą informacje wyżej. W przypadku konieczności zmiany stanu wyjścia telegramy są również wysyłane natychmiast. Z uwagi na takie zachowanie nie ma tutaj czasu na synchronizację.
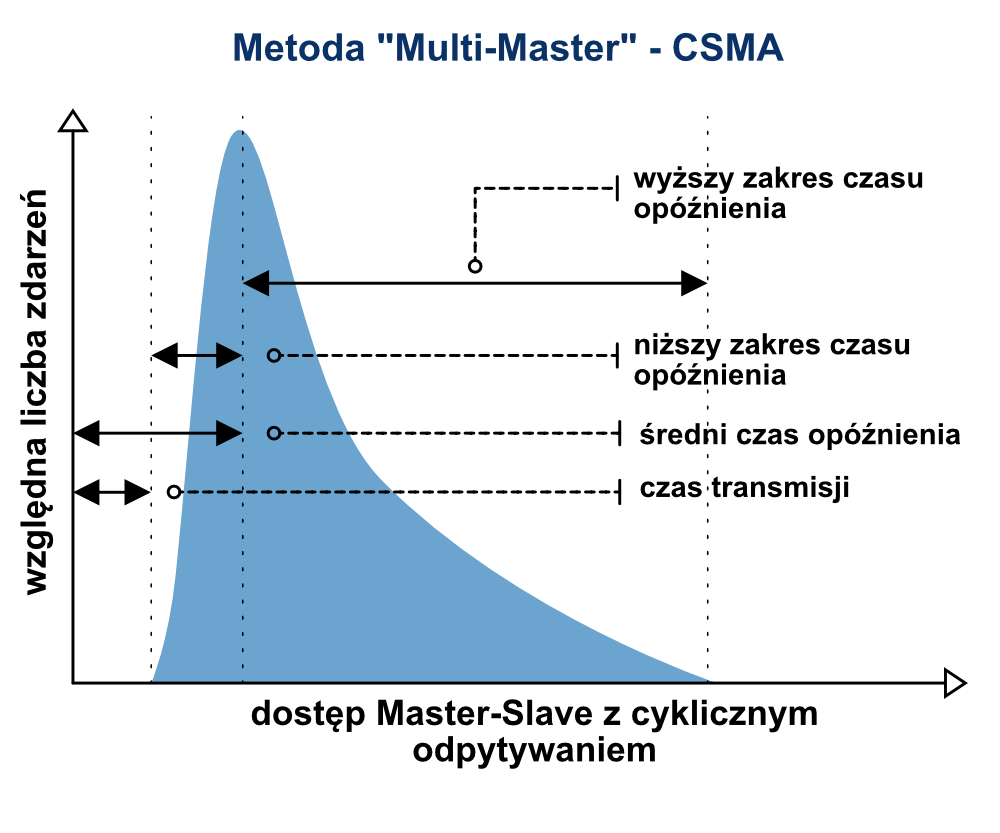
Tak czy inaczej opóźnienie wystąpi zawsze, w momencie zajętości kanału transmisyjnego przez inny telegram, w chwili żądania transmisji zgłoszonego przez kolejne urządzenie sieciowe. W związku z tym nie jest prosto określić maksymalny czas opóźnienia jakiego możemy się spodziewać w systemie opartym na tej metodzie dostępu.
Analizując to rozwiązanie w dłuższym okresie czasu można wyłonić obraz jak na powyższym rysunku. Wynik ten jest jednak silnie uzależniony od średniego obciążenia sieci. Mówiąc ściśle, metoda CSMA nie jest w żaden sposób metodą deterministyczna, ponieważ maksymalny czas opóźnienia nie może być dokładnie oszacowany. Tylko z zachowaniem maksymalnych rezerw w szerokości pasma transmisyjnego jesteśmy w stanie oszacować efektywne i maksymalne opóźnienie.
Podsumowując: całkowity czas reakcji automatycznego systemu sieciowego jest kombinacją różnych okresów czasowych, które znamy, oraz okresów opóźnienia lub synchronizacji o losowym czasie występowania. W wyniku tej kombinacji uzyskujemy średni czas reakcji z rozrzutem wokół tej wartości, który nazywamy jitterem. Obie te wartości mają ogromne znaczenie przy projektowaniu systemu sieciowego dla konkretnej aplikacji.
Zdolność do pracy w czasie rzeczywistym, synchronizacja;
Zdolność do pracy w czasie rzeczywistym jest kolejnym ważnym kryterium doboru odpowiednich komponentów automatyki przemysłowej. W przypadku systemów sterowania opartych na rozwiązaniach sieciowych (chociaż nie tylko takich) bardzo istotne jest, aby całkowity czas reakcji był krótszy niż minimalny, niezbędny czas potrzebny do monitoringu i sterowania procesem produkcyjnym. W niektórych przypadkach zbyt długi czas synchronizacji jest traktowany jako zakłócenie. Dlatego też omawiany “czas rzeczywisty” jest zawsze wartością względną, silnie zależną od innych czynników.
Dla wielu systemów produkcyjnych całkowity czas reakcji systemu sterowania na poziomie kilku sekund jest wystarczający. Przykładem takiej aplikacji będzie na pewno kontrola poziomu wody w zbiorniku ciśnieniowym. W przypadku takiego zastosowania wszystkie przedstawione powyżej systemy będą posiadały “zdolność do pracy w czasie rzeczywistym”.
Pojawia się jednak coraz więcej procesów, które wymagają znacznie szybszej reakcji, zawierającej się w kilku milisekundach. W przypadku takich aplikacji konieczne jest dokładniejsze przeanalizowanie, czy zachowanie systemu w tzw. czasie rzeczywistym jest osiągalne w każdych warunkach. Oczywiście, jak zawsze, możliwe jest “przewymiarowanie” całego systemu sterownia. W takich przypadkach wszystkie informacje podane poniżej nie znajdą zastosowania, ale istnieje bardzo duże prawdopodobieństwo, że takie “przewymiarowane systemy” będą rozwiązaniami znacznie droższymi niż systemy zoptymalizowane.
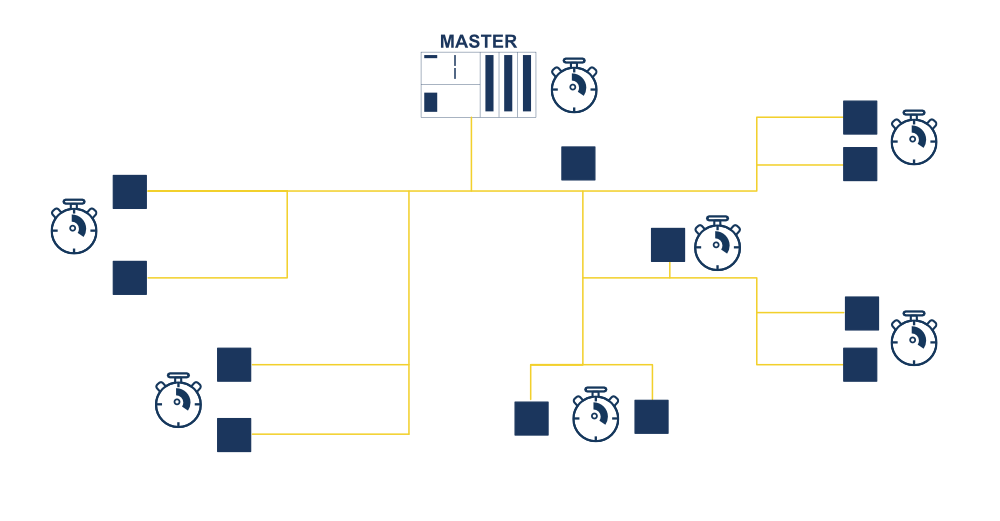
Jeśli dla danej aplikacji rozrzut wokół średniego całkowitego czasu reakcji jest zbyt duży, możliwe jest jego zmniejszenie poprzez synchronizację. Może być ona osiągnięta przez implementację stałego impulsu synchronizacji, do którego odnoszą się wszystkie działania, albo przez użycie rozproszonych zegarów synchronizacji dla każdego uczestnika wymiany danych w systemie sieciowym.
Sama synchronizacja umożliwia zbieranie stanów roboczych ze wszystkich obszarów instalacyjnych w tym samym czasie, czy też w równych odstępach czasowych, a także może zapewnić wykonywanie różnych operacji dla wielu urządzeń wykonawczych dokładnie w tym samym czasie. Sama ta cecha jest szczególnie istotna dla bardzo wielu procesów pomiarowych i kontrolnych.
|
Synchronizacja nie jest w stanie zredukować całkowitego czasu reakcji systemu! |
|
Poziom utraty danych, poziom błędów resztkowych;
Nie ma takiej technologii wymiany danych, która zapewnia transmisję bez żadnej utraty informacji i błędów komunikacji. Szczególnie w środowiskach przemysłowych, w których występuje duże zagęszczenie urządzeń elektronicznych i elektrycznych o dużej mocy, należy liczyć się z oddziaływaniem mogącym negatywnie wpływać na transmisję danych.
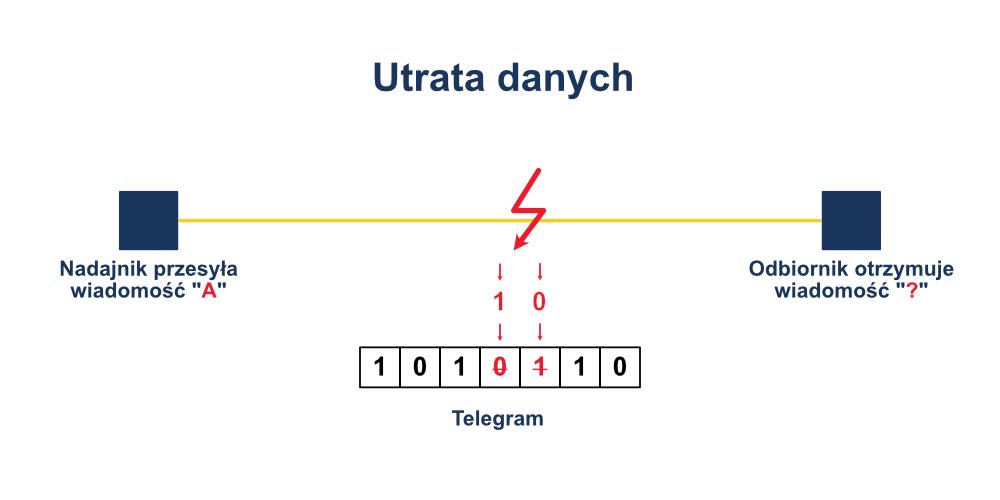
Z uwagi na ten fakt konieczne jest założenie, że zakłócenia wpływające na jakość transmisji, czy też sam tor transmisyjny, są w stanie losowo zafałszować poszczególne bity danych w przesyłanym telegramie. Przykładowo, jak na powyższym rysunku, zamiana 0 na 1, i odwrotnie, powoduje przesłanie całkiem innego telegramu.
Warto wspomnieć, że stosowanie światłowodów oferuje tylko ograniczone wyjątki od powyższej reguły. Zarówno nadajnik jak i odbiornik muszą być zasilane prądem, a przewody zasilające mogą przenosić zakłócenia. Możliwe jest zatem, że sprzężenie zwrotne do nadajnika lub odbiornika spowoduje błędy w transmisji danych.
Jeśli zakłócenia wpływają na system transmisji w sposób losowy, można wyznaczyć tzw. zakres błędów bitowych “p” dla danego obwodu transmisyjnego.
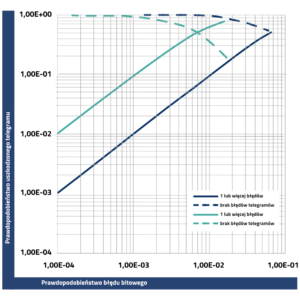 |
Dla uproszczenia przyjmijmy, że każda wiadomość, której dotyczy jedno takie zafałszowanie, jest rozpoznawana jako błędna. Współczynnik utraty danych obliczany jest jako stosunek liczby błędnych telegramów do całkowitej liczby przesyłanych wiadomości. Łatwo więc zauważyć, że w tych samych warunkach transmisyjnych dłuższe wiadomości będą znacznie bardziej narażone na błędy niż wiadomości krótkie. Z uwagi na ten fakt wskaźnik utraty danych jest wyższy w przypadku telegramów długich. Powyższy rysunek pokazuje tę zależność dla obu typów telegramów.
Wszystkie wiadomości rozpoznane jako błędne muszą być natychmiast odrzucone, ponieważ dokładna lokalizacja powstania błędu transmisyjnego nie jest możliwa do określenia. W teorii możliwe jest “naprawienie” błędnych komunikatów poprzez zastosowanie mechanizmów kodowania, wzbogaconych o procedury korekcji błędów. W praktyce jednak zajmuje to zbyt wiele czasu i jest rzadko wykorzystywane w systemach sieciowych. W tego typu systemach wszystkie wiadomości rozpoznane jako obarczone błędem muszą zostać przesłane powtórnie. Ponieważ krótsze telegramy są mniej wrażliwe na zakłócenia, czasy opóźnień wynikające z utraconych wiadomości są krótsze. Tym samym krótszy jest jitter.
|
Wskaźnik utraty danych dla określonej wartości współczynnika błędów bitowych jest istotnym kryterium oceny jakości systemu sieciowego, mającego być zastosowanym w typowym środowisku przemysłowym. |
|
Poziom błędów resztkowych
Jeśli dana wiadomość obarczona jest znaczną i rosnącą liczbą błędów bitowych, to możliwy staje się scenariusz, że odbiornik nie będzie w stanie odróżnić wiadomości zafałszowanej od poprawnej. Innymi słowy: odbiornik, otrzymując określony telegram, przyjmie go jako poprawny, co może skutkować błędami w działaniu całego systemu.
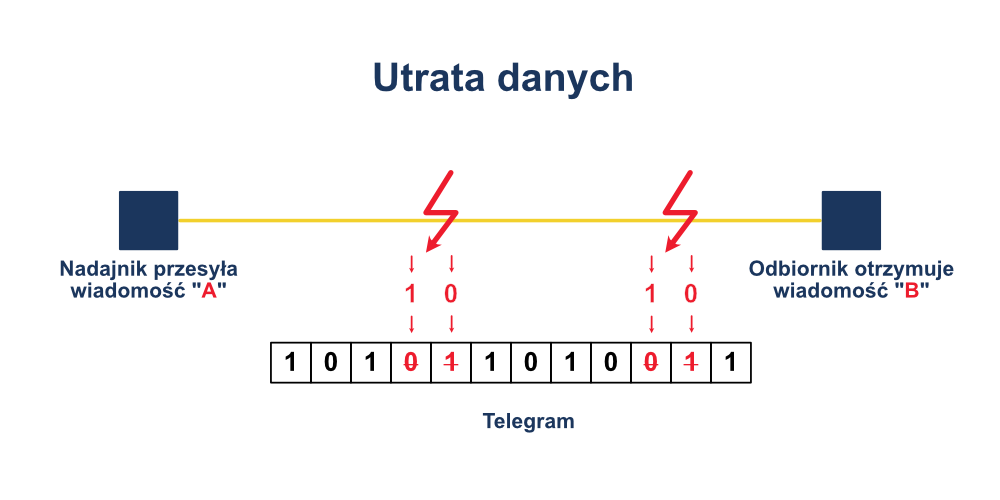
Przykładem takiej błędnej interpretacji będzie uprzednio przytoczony przykład aplikacji kontroli napełnienia. Nadajnik wysyła komunikat “A”, który oznacza “Osiągnięto górny poziom napełniania zbiornika”. Natomiast odbiornik, z uwagi na nawarstwiające się zakłócenia w sieci, otrzymuje telegram “B”, oznaczający np. “Zbiornik jest pusty”. W takim przypadku konsekwencje są potencjalnie bardzo niebezpieczne, a tym samym taka błędna interpretacja musi być powstrzymana za wszelką cenę.
Miarą takich niebezpiecznych zdarzeń jest tzw. poziom błędu resztkowego, który określa prawdopodobieństwo wystąpienia pełnego zafałszowania w przesyłanych telegramach. Naszym celem jest zawsze zredukowanie poziomu błędu resztkowego do absolutnego minimum, co osiągamy poprzez zabezpieczenie danych (data safeguarding).
W takim schemacie postępowania nadajnik dodaje do telegramu sieciowego dodatkowe dane testowe lub zabezpieczające. Zadaniem odbiornika jest ocena, z wykorzystaniem dodatkowych informacji zabezpieczających, czy wiadomość została odebrana bez żadnych błędów. Jeśli wynik takiej oceny jest negatywny, cały telegram jest odrzucany i następuje żądanie powtórzenia nadania wiadomości.
Zabezpieczenie danych
Powszechnie stosowane środki zabezpieczenia danych:
1. Bit Parzystości
Do każdego telegramu dołączany jest bit zabezpieczający.
Nadajnik i odbiornik uzgadniają parzystość telegramu. Bit zabezpieczający jest wówczas dodawany do każdej wiadomości, a jego występowanie gwarantuje poprawność sumy kontrolnej dla całego telegramu. W konsekwencji możliwe jest wykrycie wszystkich błędów, w których zmianie uległa nieparzysta liczba bitów.
Strategia ta zawodzi w przypadku wystąpienia parzystej liczby błędów (2 i więcej). Odległość Hamminga dla tego środka zapobiegawczego wynosi 2.
2. Zabezpieczenie blokowe
Każdy z telegramów ma nie tylko bit parzystości dołączony do każdego bajtu, ale także kolejny bajt danych zabezpieczających dodawany na końcu.Można wykazać, że w przypadku zabezpieczenia blokowego, 1, 2 i 3 błędy transferu są wykrywane w sposób niezawodny.
Strategia ta zawodzi tylko w przypadku wystąpienia 4 lub więcej błędów transmisji. Odległość Hamminga dla tej metody wynosi 4.
3. CRC – kontrola cykliczna
Procedura ta oparta jest na generatorze wielomianu uzgodnionym między nadajnikiem i odbiornikiem.
Telegram jest dzielony przez generator wielomianu, a reszta danych dołączana jest do wiadomości jako informacja zabezpieczająca. W przypadku bezbłędnego dostarczenia przesyłanych danych powtórzenie tego obliczenia daje zawsze wynik 0.
Zaletą tej procedury jest możliwość wyboru odległości Hamminga poprzez dobór odpowiedniego wielomianu.
|
Istnieją dodatkowe sposoby wykrywania błędów transmisji. Procedury takie wykorzystują redundancję (powielenie) kodowania sygnałów do rozpoznawania zafałszowanych wiadomości |
|
Klasy integralności danych
Norma EN 60870-5-1 definiuje trzy klasy integralności danych, z których korzystamy do określenia bezpieczeństwa przesyłanych wiadomości.

| Klasa | Poziom bezpieczeństwa | Właściwości systemu |
| I1 | Najniższy | Cykliczne powtarzanie wiadomości; |
| I2 | Średni | Wiadomości są przesyłane tylko raz; |
| I3 | Najwyższy | Aplikacje krytyczne z uwagi na bezpieczeństwo; |
Kategoria I1 jest przeznaczona dla systemów, które cynicznie przetwarzają komunikaty sieciowe. Kategoria I2 jest stosowania w systemach, gdzie telegramy przesyłane są tylko jeden raz. W przypadku kategorii I3 mówimy o aplikacjach o krytycznym znaczniu dla bezpieczeństwa.
Poziom błędów resztkowych zależy do następujących parametrów:![]() prędkości transferu
prędkości transferu![]() długości telegramu
długości telegramu![]() poziomu błędów bitowych
poziomu błędów bitowych ![]() strategii zabezpieczenia danych
strategii zabezpieczenia danych
Z uwagi na te zależności, określenie poziomu błędów resztkowych nie jest zadaniem prostym.
|
Poziom błędów resztkowych jest jedynym użytecznym parametrem do oceny ryzyka zafałszowania danych oraz do określenia integralności danych w określonej aplikacji. Wspomniana uprzednio Odległość Hamminga nie jest odpowiednim parametrem zastępczym dla tego zadania. |
|
Nawiasem mówiąc, poziom błędów resztkowych jest odwrotnie proporcjonalny do wydajności przesyłu danych w magistrali. Im bezpieczniejsza musi być ta transmisja, tym niższa jest dostępna przepustowość danych i tym też niższa jest wydajność.
Różnorodność, modularność i inne aspekty ekonomiczne;
Różnorodność i modularności systemu sieciowego oznacza najmniejszy możliwy rozmiar jednostek wejściowych i wyjściowych. Z reguły nie jest to zagadnienie czysto techniczne, a przede wszystkim ekonomiczne.
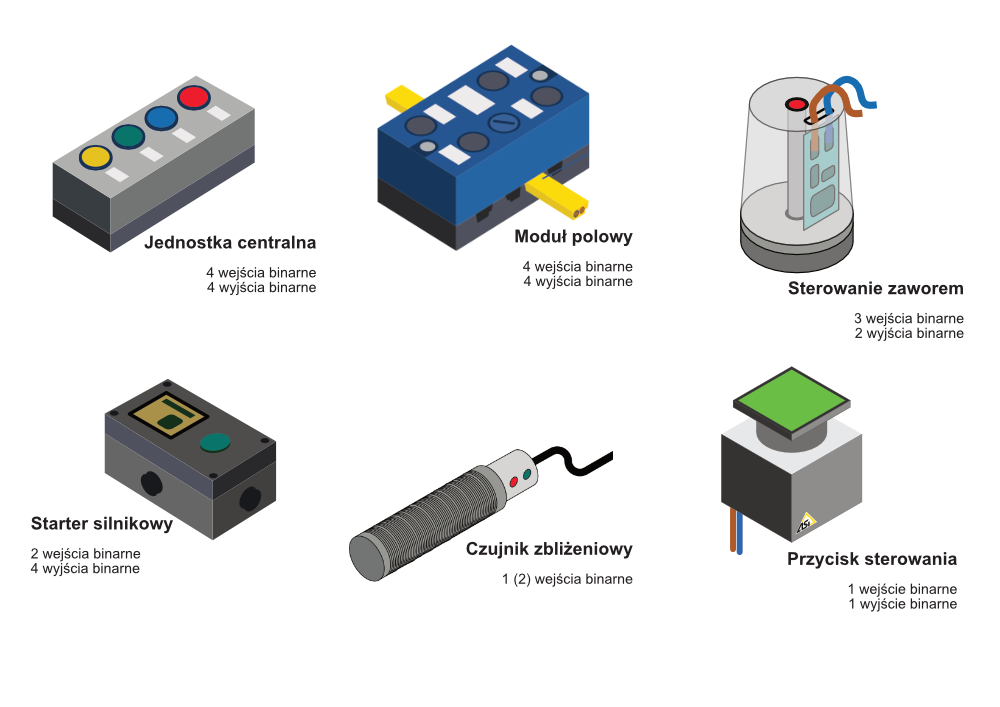
Poznaliśmy już ogólny podział systemów sieciowych na systemy zorientowane bitowo, bajtowo lub blokowo. Właśnie z tego podziału wynikać będzie bezpośrednia możliwość ekonomicznego dołączania kolejnych, jak najmniejszych, urządzeń. Dotyczy to przyłączenia np. czujnika indukcyjnego czy też wskaźnika diodowego (prostej lampki sygnalizacyjnej).
Do zalet zwiększonej różnorodności i modularności systemu zaliczamy:
![]() możliwość dokładnego dopasowania do rzeczywistej wymaganej liczby wejść i wyjść. Dzięki temu unikamy niewykorzystanych kanałów i związanych z nimi niepotrzebnych kosztów;
możliwość dokładnego dopasowania do rzeczywistej wymaganej liczby wejść i wyjść. Dzięki temu unikamy niewykorzystanych kanałów i związanych z nimi niepotrzebnych kosztów;
![]() liczba niezbędnych wariantów danego urządzenia może być utrzymana na niskim poziomie. Jest to korzystne nie tylko dla producentów tych urządzeń, ale również dla użytkownika, zarówno na etapie projektowania i zakupu jak również instalacji i późniejszego zarządzania częściami zamiennymi.
liczba niezbędnych wariantów danego urządzenia może być utrzymana na niskim poziomie. Jest to korzystne nie tylko dla producentów tych urządzeń, ale również dla użytkownika, zarówno na etapie projektowania i zakupu jak również instalacji i późniejszego zarządzania częściami zamiennymi.
Należy pamiętać, że parametry techniczne i koszty samego sprzętu nie są jedynymi czynnikami w procesie wyboru systemu sieciowego. Istnieją czynniki dodatkowe, bardzo istotne z ekonomicznego punktu widzenia, ale dość trudne do sklasyfikowania. Do takich parametrów zaliczamy:
Wymagania dotyczące szkoleń
Podczas fazy wdrażania systemu sieciowego wymagane są szkolenia dla pracowników i powinny one być minimalne. Sam system powinien być prosty w obsłudze i zrozumieniu.
Elastyczność podczas projektowania i montażu
Podczas samego projektowania system powinien wymagać przestrzegania minimalnej ilości ograniczeń. Upraszcza to cały proces, eliminuje ewentualne błędy, skraca czas realizacji projektu i pozwala uzyskać wysoki poziom elastyczności przy późniejszych zmianach i rozbudowie.
Wsparcie dla modułowej budowy maszyn i systemów produkcyjnych
System sieciowy powinien zawsze wspierać modułową budową maszyn i linii produkcyjnych. Umożliwia to wykorzystanie prefabrykowanych i przetestowanych modułów do szybkiego i bardzo efektywnego składania systemów charakteryzujących się wysokim stopniem złożoności.
Duża różnorodność dostępnych produktów
Zawsze preferowana jest duża różnorodność środków technicznych (modułów) dostępnych od różnych dostawców. Umożliwia to użytkownikowi wybór najlepszego produktu do konkretnego zastosowania. Jeśli np. produkty nadają się do montażu polowego, w aplikacjach charakteryzujących się surowymi warunkami środowiskowymi, to niekonieczne będzie stosowanie specjalnych obudów lub, w najgorszym przypadku, można zmniejszyć ich rozmiary i ilość.
Instalacja, diagnostyka i konfiguracja
Produkty powinny być proste do podłączenia (“plug and play”), dostarczać szczegółowych danych diagnostycznych oraz oferować automatyczną konfigurację w przypadku konieczności wymiany. Pomaga to w znacznym zminimalizowaniu kosztów związanych z przestojami.
Trwałość i bezpieczeństwo samej inwestycji
Wybrany standard sieciowy powinien oferować wysoki poziom stabilności oraz bezpieczeństwo inwestycji w dłuższym okresie czasu. Maszyna, czy też cała linia produkcyjna, będzie wykorzystywana przez wiele lat. W całym czasie życia konieczne jest utrzymanie kompatybilności różnych systemów sieciowych.
Na tym kończymy wstęp teoretyczny dotyczący samych systemów sieciowych. Podane tutaj informacje są podstawowe i nie odnoszą się do żadnego konkretnego rozwiązania. Informacje te są natomiast bardzo istotne na etapie wyboru określonego środka technicznego. W kolejnych częściach skupimy się już tylko na sieci AS-Interface, wyjaśniając dokładnie w szczegóły techniczne pracy tego interfejsu. Informacje podstawowe znajdą Państwo TUTAJ – jest to artykuł wprowadzający i uproszczony, wyjaśniający cechy AS-Interface i korzyści płynące z zastosowania właśnie tej technologii.